







Das eingebettete Video wird von Vimeo bereitgestellt und startet bei Klick. Es gelten die Datenschutzerklärungen von Vimeo https://vimeo.com/privacy

Unsere Definition von All-in-One SEO-Tool:
+0
APIs
+0
Funktionen
+0
User
+0
Websites
+0
Sprachen
Ihr gesamtes SEO in der Hosentasche – immer mit dabei
Devices
Sie können die App auf dem Handy und Tablet kostenlos nutzen. Mit Apple und Android Geräten!
Datawarehouse
Binden Sie alle gängigen Tools einfach und schnell an: GSC, Analytics, GMB, Google Ads, Bing, uvm.
Automatisierung
Mit der Performance Suite arbeiten Sie effizienter und besser!
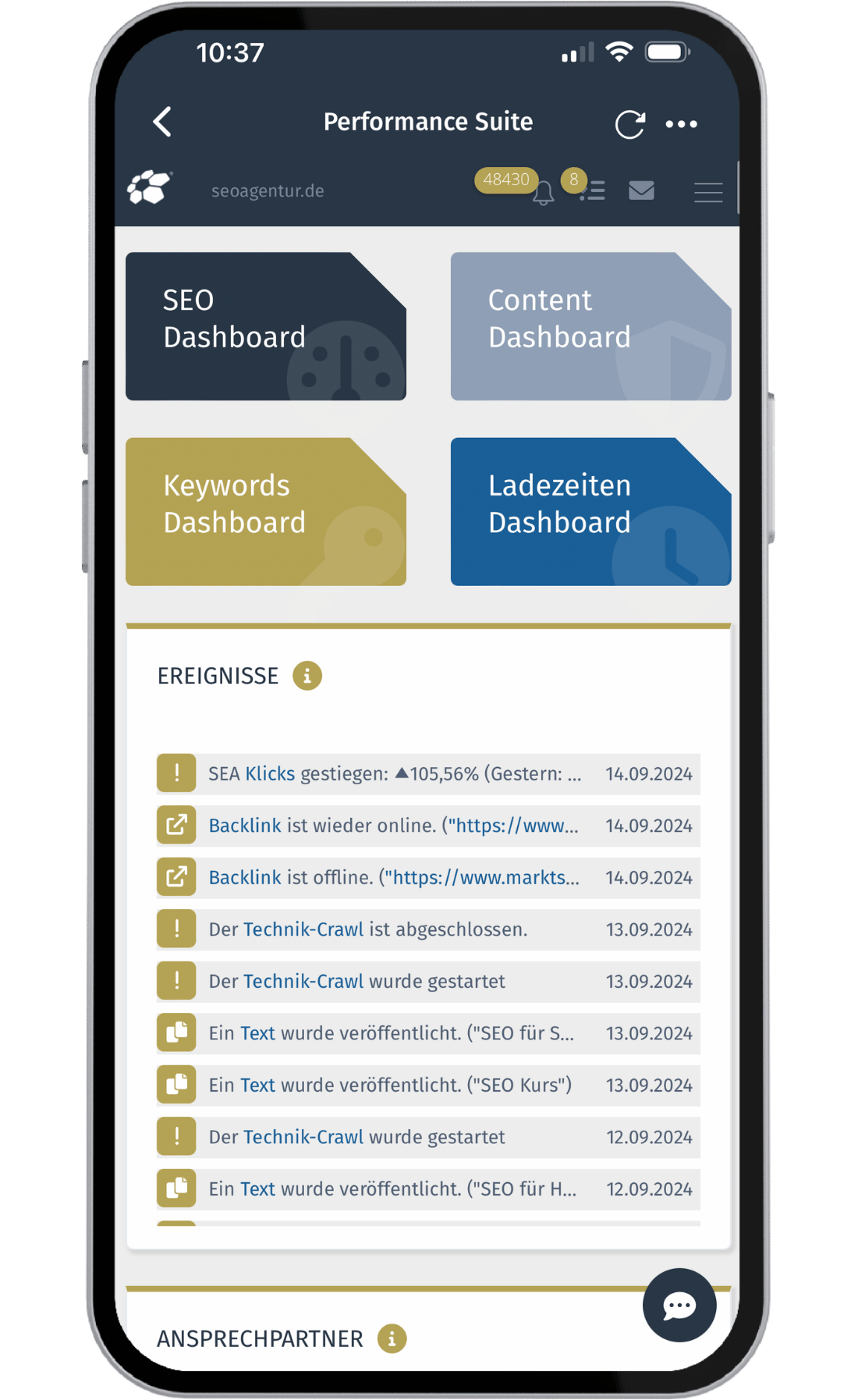
Alle SEO Funktionen in einer Lösung
SEO-Tool für Keywords, Content, Backlinks, Technik, Security, Alert-System, ROI-Messung uvm.
Push-Nachrichten
Sie, Ihr Team und Ihre Dienstleister werden bei Problemen und Ereignissen sofort informiert.
Jetzt Free Version downloaden


Das sagen andere über uns
100 Prozent Data-Driven
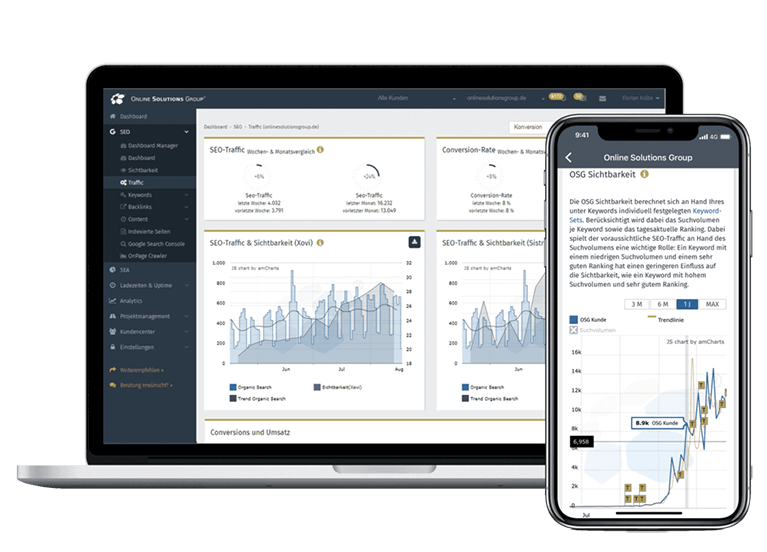
In kaum einem anderen Online-Marketing-Bereich wird so viel gemutmaßt wie im SEO. Ein bekanntes Sprichwort sagt: „Zwei SEOs – Drei Meinungen“. So hört man immer wieder „die Keyworddichte wäre tot“, „die Wirkung von Backlinks sei homöopathisch“ oder „die optimale Textlänge läge bei 1.200 Wörtern“. All diese Aussagen sind falsch und ohne jegliche Datenbasis. Ursache des Problems ist, dass es bislang kein Tool wie die Performance Suite (PS) gab. Unser SEO Tool ermittelt datengetrieben und 100 % nachvollziehbar, auf welche Werte es ankommt.
So crawlen wir z. B. am Tag mehrere Millionen Seiten, um zu erforschen, warum bestimmte URLs bei Google für spezielle Keywords gut ranken. Die PS ermittelt so unter anderem pro Keyword, welche Textlänge optimal ist und was es sonst noch zu beachten gilt. Die Erfolge sprechen für sich: Über 90 % der erstellten Texte landen in der Regel innerhalb weniger Tage in der Top 5 bei Google. Die integrierte Erfolgskontrolle ermittelt automatisch, welche Auswirkung ein erstellter Text, ein Backlink oder eine technische Änderung auf die SEO-Performance hatte.
Das zentrale Betriebssystem für Ihr SEO - mit über 800 Funktionen
Ein SEO-Tool für alles
Mit der Performance Suite profitieren Sie von allen relevanten Funktionen die Sie im SEO benötigen - in einer Lösung. Nutzen Sie so wichtige Synergien und sparen Sie wertvolle Zeit und Kosten.
Prozessoptimierung
Die Performance Suite bietet nicht nur über 800 Funktionen, sondern optimiert auch Ihre Prozesse in der SEO. So werden Ihre Workflows verbessert und Fehler weitestgehend reduziert.
Unbegrenzt viele User
In der Performance Suite kann Ihr gesamtes Team übersichtlich zusammenarbeiten. Das SEO-Tool macht es leicht, alle Beteiligten über die wichtigsten Aufgaben zu informieren. und die To Do’s besser zu verwalten.
Data Warehouse
Dank Schnittstellen zur Google Search Console, zu Google Ads, Google My Business, Analytics, Bing Webmaster Tools u.v.m. können Sie Ihre Tools in die PS einbinden und haben alles gesammelt an einem Ort!
Gezielte Optimierung
Mit der Performance Suite lässt sich Ihr SEO gezielt optimieren. Zahlreiche Checks, entstanden aus über 15 Jahren Agenturerfahrung, sorgen für reibungslose Abläufe und eine Erhöhung der Qualitätsstandards.
Dienstleister-Funktion
Integrieren Sie Ihre Dienstleister (bspw. Programmierer, Texter, Designer) in Ihre Projekte in der Performance Suite. So ist eine direkte und schnelle Zusammenarbeit möglich und alle Beteiligten sind informiert.
Integriertes Alert-System
Erhalten Sie in Echtzeit Alerts per Mail oder Push-Benachrichtigungen, um bei Problemen oder Down-Time zeitnah handeln zu können. Verpassen Sie nie wieder, was bei Ihrem Projekt passiert!
Multi Domain
Behalten Sie immer den Durchblick - auch bei mehreren Domains. Dank unseres SEO-Tools können Sie mehrere Domains integrieren und Ihr Projekt im eigenen Management im Blick behalten.
Mehr Sicherheit
Wir sorgen für die automatisierte technische Absicherung in allen Bereichen: Ladezeiten, Uptime, Security und SEO-Technik. So bleibt Ihnen mehr Zeit für kreative Aufgaben, die sich nicht automatisieren lassen.
Aktuelle Studien
Die Performance Suite – The Future of SEO!
Die Performance Suite bietet die Grundlagen für ein zukunftsfähiges SEO. Für kleine wie große Firmen wird sich unser All-in-One SEO-Tool als das zentrale SEO-Betriebssystem etablieren. Herkömmliche SEO-Tools werden sich als nachrangige Anwendungen erweisen, da die Performance Suite quasi alle relevanten Funktionen für ganzheitliches SEO und maximale Automatisierung bietet.
Durch das integrierte Data Warehouse werden völlig neuartige Synergien im SEO ermöglicht. Die Datenmengen werden immer komplexer. Allein Google stellt mit der Search Console, Google Analytics, Google Ads und Google Unternehmensprofile (früher Google My Business) schon vier verschiedene und wichtige Tools zur Verfügung. Auch die Anforderungen an exzellente Technik, hochwertigen Content und hervorragende Backlinks werden immer höher. Diese Herausforderungen werden künftig nur mit Künstlicher Intelligenz und smarten Technologien zu bewältigen sein. Mit der Performance Suite sind Sie heute fit für den Wettbewerb von morgen! Unser SEO-Management-Tool hilft Ihrem Unternehmen, SEO zu automatisieren und zu verbessern. Völlig egal, ob Sie SEO inhouse oder mit einer SEO-Agentur umsetzen, Sie sparen Zeit, Kosten und verbessern Ihre SEO-Performance signifikant. Außerdem kann die Performance Suite als Enterprise-SEO-Tool ohne Vorkenntnisse genutzt werden, da sie über 4.000 Erklärtexte auf über 20 Sprachen verfügt.
Überzeugen Sie sich selbst von unserem SEO Tool. Sie können den Free-Account dauerhaft kostenlos nutzen.
Weitere Vorteile:
Anbindung aller relevanten SEO-Tools
Mittels APIs können Sie die Daten aller gängigen SEO-Tools nutzen und so von noch besseren Analysen profitieren.







Preisübersicht Performance Suite
Stellen Sie sich passgenau die Module zusammen, die Sie benötigen: Erweitern Sie beispielsweise Ihren Premium Account um die umfangreiche Content Suite zum Erstellen hochwertiger SEO-Texte. In der Backlink Suite setzen Sie mithilfe von KI professionelles Linkbuilding um. Die Preise sind netto pro Monat.
Free Account
Performance Suite mit limitierten Funktionen
- ✓ Dauerhaft kostenlos
- ✓ Bis zu 5 User
- ✓ Künstliche Intelligenz
- ✓ Keyword Tool
- ✓ Push-Nachrichten & Alerts
- ✓ Ladezeiten-Tool
- ✓ Technik-Crawler
- ✓ Uptime-Checker
- ✓ Security-Crawler
- ✓ Marktanalyse
kostenlos
Premium Account
Die mächtige Performance Suite für Ihren Erfolg im Online-Marketing
- ✓ Anzahl User unbegrenzt
- ✓ Vollständiges Keyword Tool
- ✓ APIs zu GSC, GMB, SEA, Bing
- ✓ Push-Nachrichten & Alerts
- ✓ Technik-Crawler
- ✓ Security-Crawler
- ✓ Ladezeiten-Tool
- ✓ Uptime-Check
- ✓ Projektmanagement
- ✓ Nutzerverwaltung
- ✓ Brand Protection
- ✓ Marktanalyse
- ✓ Konkurrenzüberwachung
250 €
Content Suite (optional)
Zusatzmodul zum Premium Account
- ✓ Unbegrenzt viele Texte schreiben und verwalten
- ✓ GPT4-Integration
- ✓ Prüfung aller SEO-Faktoren
- ✓ Automatische Erfolgsprüfung
- ✓ Check auf Duplicate Content
- ✓ Rechtschreibung, Grammatik, eigenes Wörterbuch
- ✓ Eigener Bilder-Pool mit automatischer Komprimierung
- ✓ Füllwörter, Modalverben, Wortanzahl
- ✓ Passende Fragen und verwandte Suchbegriffe über API
- ✓ Content-Scoring
- ✓ Automatischer Content-Audit
+100 €
Backlink Suite (optional)
Zusatzmodul zum Premium Account
- ✓ Backlinks verwalten
- ✓ Wettbewerber vergleichen
- ✓ Automatische Erfolgsprüfung der Backlinks
- ✓ Monitoring aller Backlinks
- ✓ Empfehlungen für neue Backlinks
- ✓ Tipps für Linkbuilding
- ✓ Partnernetzwerk
- ✓ Mailing Tool für Akquise
- ✓ Auswertungen & Analysen
- ✓ Keyword-Analysen
- ✓ Wettbewerber-Analysen
- ✓ Automatisches Backlink-Rating
+100 €
Service und Consulting (optional)
Optional OSG als Agentur buchen
- ✓ Individuelle Beratung
- ✓ Konzeptentwicklung
- ✓ Hilfe beim Linkaufbau
- ✓ Texterstellung durch eigene Redaktion
- ✓ Onboarding
- ✓ Workshops
- ✓ Beratung in allen Online-Bereichen
- ✓ 50% staatliche Förderung möglich (go digital)
Nach Aufwand
SEA-Modul (optional)
- ✓ Google Ads Konto verknüpfen
- ✓ Wettbewerber-Analysen
- ✓ Monitoring Ihrer Kampagnen
- ✓ Empfehlungen für Optimierungen
- ✓ Tipps für SEA
- ✓ Auswertungen & Analysen
- ✓ Keyword-Analysen
- ✓ SEA/SEO-Synergien
- ✓ Budgetmanagement
- ✓ Landingpage-Checks
- ✓ Conversionberichte
- ✓ Anzeigenberichte
+100 € +0 €*
*gilt bis Ende April
Das spricht für unser All-in-One SEO-Tool
Über 1.000 € im Monat sparen
Maximale SEO-Performance
Automation
Holen Sie sich Ihr neues SEO-Tool! Die Zukunft von SEO beginnt jetzt!
Jetzt Free Account erstellen
Jetzt kostenlose Demo anfordern

